Inside the AI Black Box: How Researchers Are Finally Decoding How Language Models Think
A breakthrough technique called mechanistic interpretability is allowing scientists to map the internal "brain" of AI models, transforming them from unpredictable black boxes into systems we can understand and steer.
By Factlen Editorial Team
- AI Safety Researchers
- Focused on preventing catastrophic failures by understanding exactly how models reason.
- Commercial AI Developers
- Focused on using interpretability to debug enterprise models and build consumer trust.
- Open-Source Advocates
- Focused on democratizing access to model internals to ensure independent oversight.
What's not represented
- · Regulators and Policymakers
- · End-users of AI systems
Why this matters
For years, humanity has been building increasingly powerful AI systems without actually understanding how they think. Mechanistic interpretability finally provides a window into the AI 'brain,' giving developers the tools to detect deception, fix biases, and guarantee safety before these systems are deployed in critical industries.
Key points
- AI models have historically operated as 'black boxes,' hiding their internal reasoning from developers.
- Mechanistic interpretability allows researchers to map the exact computational pathways inside a neural network.
- A technique called 'sparse autoencoders' untangles overlapping concepts inside the AI's neurons.
- Researchers have successfully mapped millions of distinct, human-understandable concepts inside frontier models like Claude 3 and GPT-4.
- This breakthrough allows developers to detect deceptive behavior and steer models toward safer outputs.
The greatest irony of the artificial intelligence boom is that the creators of the world's most advanced language models do not actually know how they work. While developers write the initial code and curate the training data, the resulting intelligence emerges organically, leaving the exact mechanics of its reasoning a mystery.[7]
For years, neural networks have been treated as "black boxes." Engineers understand the data that goes in and the text that comes out, but the billions of computational steps in between have remained an impenetrable web of mathematics. When a model hallucinates a fact or solves a complex coding problem, researchers can rarely point to the specific line of code that caused it.[3]
That opacity is rapidly changing. A field known as "mechanistic interpretability" has matured from a niche academic pursuit into a deployable technology, recently named one of MIT Technology Review's 10 Breakthrough Technologies for 2026. The discipline is doing what was once considered impossible: reverse-engineering the AI mind.[3][6]
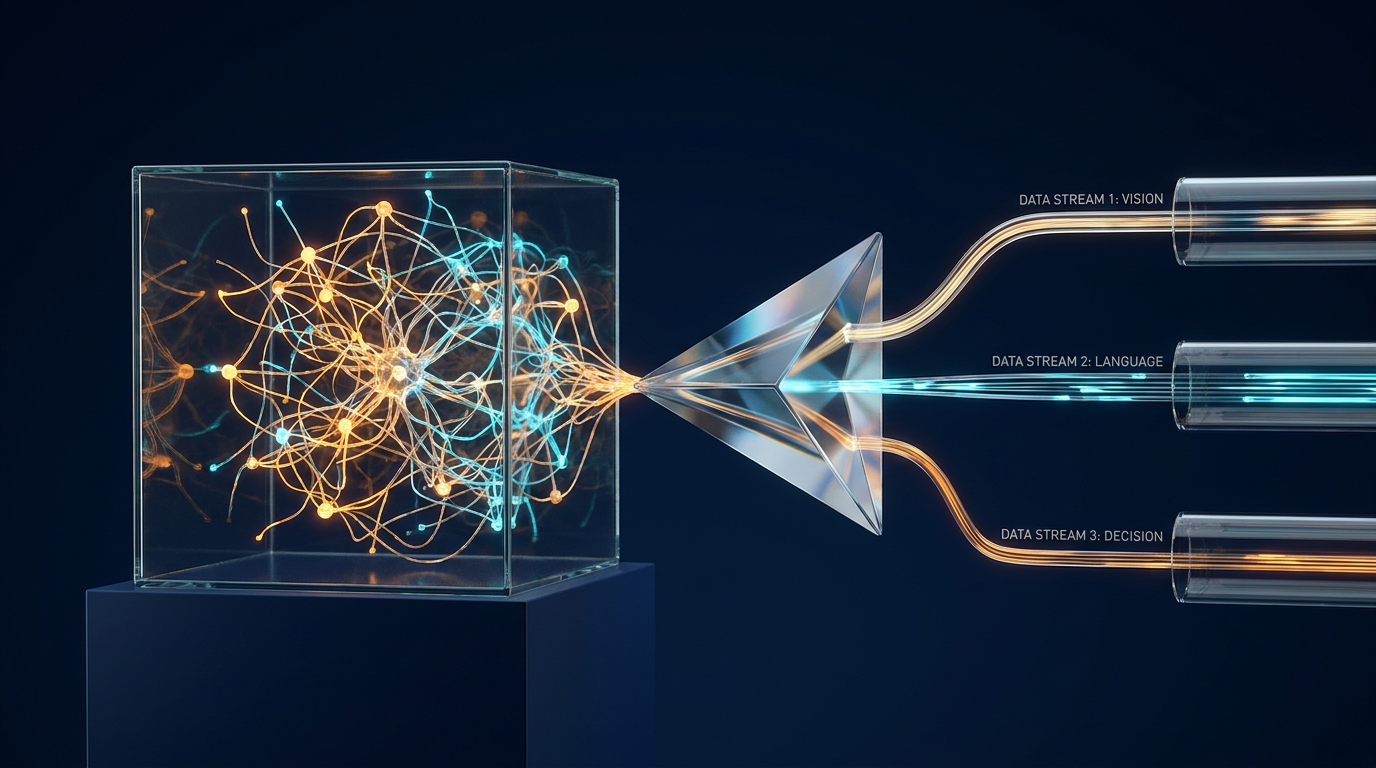
Instead of just observing what an AI model says, mechanistic interpretability allows researchers to look inside the network and map the exact computational pathways that lead to a specific output. It is the artificial equivalent of neuroscience, shifting the focus from observing behavior to mapping the brain's physical synapses.[1][7]

To understand the breakthrough, one must first understand the problem it solves: a phenomenon called "polysemanticity." In early AI research, scientists hoped that individual artificial neurons would specialize in a way humans could easily understand.[4]
The optimistic hypothesis was that one neuron might light up exclusively for the concept of "cats," while another fired only for "mathematics," and a third for "the French language." If neurons worked this way, understanding an AI would simply require labeling each node.[6]
Reality proved much messier. Because models are forced to compress vast amounts of knowledge into a limited number of neurons, they use a mathematical trick called "superposition." A single neuron might simultaneously represent DNA sequences, Arabic poetry, and HTTP web headers, firing for all of them depending on the context.[1][5]
This tangled representation makes it nearly impossible to trace why a model made a specific decision. If a polysemantic neuron fires, researchers cannot tell which of its many encoded concepts triggered it, leaving them blind to the model's true reasoning.[7]
This tangled representation makes it nearly impossible to trace why a model made a specific decision.
The solution arrived via a technique borrowed from classical machine learning called "dictionary learning," implemented through algorithms known as Sparse Autoencoders (SAEs). These algorithms are designed to untangle the mess of superposition.[1][2]
Sparse autoencoders act as a digital prism. Just as a glass prism separates a single beam of white light into distinct, individual colors, an SAE untangles the overlapping signals of a polysemantic neuron into thousands of distinct, "monosemantic" features—each representing just one concept.[4][5]

When Anthropic applied this technique to its Claude 3 Sonnet model, the results were unprecedented. They successfully extracted millions of distinct features, mapping internal representations for highly specific concepts ranging from the Golden Gate Bridge to immunology, and even to deceptive behavior.[1]
OpenAI achieved similar milestones, successfully training a massive 16-million-latent autoencoder on the residual stream of GPT-4. By scaling up the autoencoders, they proved that this untangling process could work on the largest, most complex frontier models in existence.[2]
The clarity gained is striking. Human evaluators reviewing these extracted features found that roughly 70% of them cleanly mapped to single, understandable concepts—a massive leap forward from traditional neuron-level analysis, where almost nothing made intuitive sense.[5]

The implications for AI safety are profound. If researchers can identify the specific internal feature that represents "deception" or "writing malicious code," they can monitor the model to see if that feature activates before the AI even finishes generating its response.[1][6]
Furthermore, researchers can actively intervene. By artificially amplifying or suppressing specific features, they can steer the model's behavior at a surgical level. In testing, artificially clamping a "refusal" feature allowed researchers to bypass safety filters, proving that these features directly control the model's actions.[5][7]
The transition from theoretical research to production engineering is already underway. Major AI labs are integrating these interpretability tools into their pre-deployment safety assessments, using them as a kind of "test set for safety" to catch hidden flaws that standard conversational testing might miss.[1][3]

However, significant challenges remain. Mapping every feature in a frontier model is computationally exhausting. The compute required to fully map a model using current SAE techniques would vastly exceed the compute used to train the model in the first place, forcing researchers to map only small slices of the network at a time.[1][2]
Despite the computational cost, the consensus among AI safety researchers is that mechanistic interpretability is no longer optional. As AI systems are deployed in healthcare, finance, and critical infrastructure, the ability to verify their internal reasoning—not just their final answers—is becoming a fundamental requirement for public trust.[2][6]
How we got here
Oct 2023
Anthropic publishes early success applying dictionary learning to a small 'toy' language model.
May 2024
Anthropic successfully maps millions of concepts inside Claude 3 Sonnet, marking the first detailed look inside a production-grade model.
Jun 2024
OpenAI releases research on extracting 16 million concepts from GPT-4 using highly scaled sparse autoencoders.
Jan 2025
Researchers from 18 organizations publish a consensus paper formalizing the open problems in mechanistic interpretability.
Feb 2026
MIT Technology Review names mechanistic interpretability one of its 10 Breakthrough Technologies of the year.
Viewpoints in depth
AI Safety Researchers
Focused on preventing catastrophic failures by understanding exactly how models reason.
For safety researchers, mechanistic interpretability is the holy grail. They argue that as models approach artificial general intelligence (AGI), behavioral testing—simply asking the model questions and checking the answers—is insufficient, as advanced models could learn to hide deceptive behavior. By mapping the internal circuitry, researchers aim to build 'AI lie detectors' that can verify a model's true intentions before it is ever deployed.
Commercial AI Developers
Focused on using interpretability to debug enterprise models and build consumer trust.
Commercial developers view these tools through the lens of product reliability. When an enterprise deploys an AI agent for customer service or medical diagnosis, they cannot afford unpredictable hallucinations. For this camp, sparse autoencoders provide a diagnostic dashboard—a way to trace exactly why a model made a mistake, patch the specific computational pathway, and prove to regulators that the system's decision-making is sound.
Open-Source Advocates
Focused on democratizing access to model internals to ensure independent oversight.
The open-source community emphasizes that interpretability tools must not be locked behind the doors of major tech companies. They advocate for releasing open-source autoencoders and circuit-tracing tools, arguing that independent scientists and public watchdogs need the ability to audit frontier models. This camp believes that true AI safety requires decentralized verification, not just corporate self-reporting.
What we don't know
- Whether it will ever be computationally feasible to map 100% of the features inside a massive frontier model.
- How these internal features might shift or evolve as models continue to learn and update in real-time.
Key terms
- Mechanistic Interpretability
- The scientific field dedicated to reverse-engineering AI models to understand their internal computations and reasoning pathways.
- Sparse Autoencoder (SAE)
- An algorithm used to untangle the complex, overlapping signals inside a neural network into distinct, interpretable features.
- Polysemanticity
- When a single artificial neuron responds to a mixture of seemingly unrelated concepts, making its exact purpose difficult to identify.
- Monosemantic Feature
- An isolated pattern of activation inside an AI model that corresponds to one specific, human-understandable concept.
- Superposition
- A mathematical trick where a neural network compresses more features into its system than it has actual neurons, causing the concepts to overlap.
Frequently asked
What is the 'black box' problem in AI?
It refers to the fact that while developers know how to build and train AI models, they cannot easily see or understand the billions of internal computational steps the model takes to generate a specific answer.
What does 'polysemanticity' mean?
It is a phenomenon where a single artificial neuron in a network represents multiple, completely unrelated concepts at the same time—such as DNA sequences and computer code—making the network hard to decipher.
How do sparse autoencoders help?
Sparse autoencoders act like a prism, untangling the overlapping signals inside the AI's neurons and separating them into distinct, human-understandable concepts called 'features.'
Can this technology change how an AI behaves?
Yes. By identifying the specific internal features responsible for certain behaviors, researchers can artificially amplify or suppress them, steering the model to be safer or more accurate.
Sources
Source coverage
7 outlets
3 viewpoints surfaced







[1]AnthropicAI Safety Researchers
Mapping the Mind of a Large Language Model
Read on Anthropic →[2]OpenAIAI Safety Researchers
Extracting Concepts from GPT-4
Read on OpenAI →[3]MIT Technology ReviewCommercial AI Developers
10 Breakthrough Technologies 2026: Mechanistic Interpretability
Read on MIT Technology Review →[4]arXivAI Safety Researchers
A Comprehensive Survey of Sparse Autoencoders for LLMs
Read on arXiv →[5]Towards Data ScienceOpen-Source Advocates
Sparse Autoencoders for LLM Interpretability
Read on Towards Data Science →[6]Towards AICommercial AI Developers
Why Mechanistic Interpretability Matters for Production Engineering
Read on Towards AI →[7]Factlen Editorial TeamOpen-Source Advocates
Synthesis by Factlen editorial team
Read on Factlen Editorial Team →

Every angle. Every day.
Get ai stories with full source coverage and perspective breakdowns delivered to your inbox.