The Rise of Local AI: Why Millions Are Running Language Models Offline
As cloud-based AI raises privacy and cost concerns, a growing movement of users is downloading and running powerful language models directly on their personal laptops and phones.
By Factlen Editorial Team
- Privacy Advocates
- View local AI as an essential defense against corporate data harvesting, prioritizing absolute data sovereignty.
- Open-Source Developers
- Focus on the democratization of technology, building tools that allow anyone to tinker with and run models without gatekeepers.
- Hardware Manufacturers
- See the local AI trend as a major driver for upgrading consumer hardware, emphasizing the power and efficiency of new NPU chips.
What's not represented
- · Cloud computing providers losing subscription revenue
- · Cybersecurity experts monitoring malicious uses of uncensored local models
Why this matters
Running AI locally guarantees absolute data privacy, eliminates monthly subscription fees, and allows users to access powerful digital assistants even without an internet connection. It represents a massive shift of computing power from corporate server farms back to the individual user.
Key points
- Millions of users are downloading AI models to run directly on their laptops and phones.
- Local processing guarantees absolute data privacy, as no information is sent to corporate servers.
- Techniques like quantization compress massive models to fit into standard consumer RAM.
- New Neural Processing Units (NPUs) allow laptops to run AI without draining the battery.
- Local AI eliminates monthly subscription fees and works entirely without an internet connection.
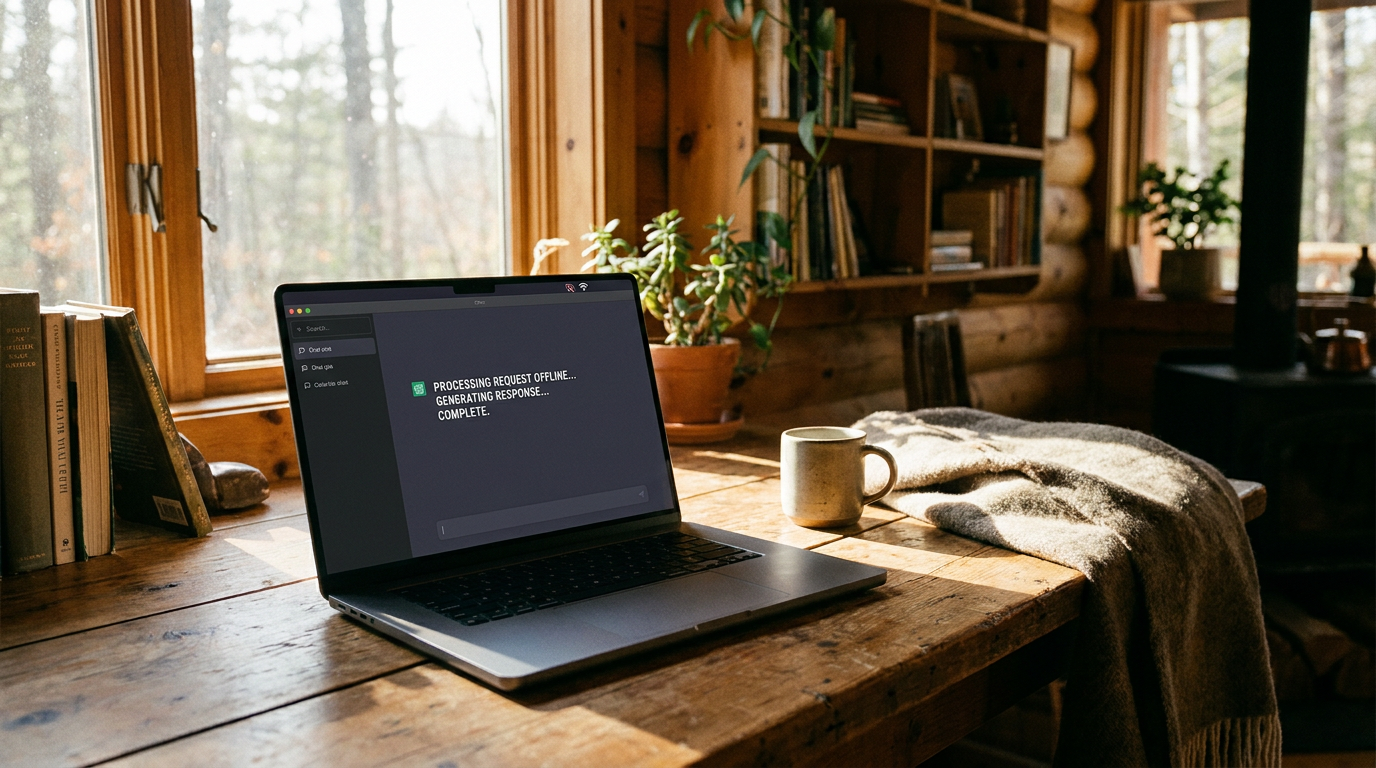
For the past few years, the artificial intelligence boom has been fundamentally tethered to the cloud. Using tools like ChatGPT or Claude meant sending every prompt, document, and personal query to massive corporate server farms for processing. But a quiet, empowering revolution has taken hold in 2026: millions of users are now downloading the "brains" of these AI systems directly to their own laptops and phones, running them entirely offline.[1][6]
This movement, known as "Local AI" or "Edge AI," flips the standard model on its head. Instead of renting access to a monolithic model housed in a distant data center, users are utilizing open-weight models that live permanently on their local hard drives. The shift is being driven by a convergence of highly optimized software, breakthroughs in model compression, and a new generation of consumer hardware designed specifically for artificial intelligence.[3][6]
The most urgent catalyst for this migration is absolute data privacy. When an AI model runs locally, the internet connection can be completely severed. This has made local AI an essential tool for lawyers analyzing confidential case files, doctors summarizing patient notes, and everyday users journaling about deeply personal matters. Because the data never leaves the device, the risk of a corporate data breach or unauthorized training ingestion is reduced to zero.[2][8]

Understanding how this is possible requires looking at the mechanics of model compression, specifically a technique called "quantization." A standard, uncompressed language model requires hundreds of gigabytes of memory to run—far more than a typical consumer laptop possesses. Quantization solves this by mathematically shrinking the precision of the model's neural weights, effectively rounding off the numbers to save space.[4][5]
By compressing these weights from 16-bit precision down to 4-bit precision, developers have managed to shrink massive AI models so they can comfortably fit into 8GB or 16GB of standard laptop RAM. Remarkably, this aggressive compression results in only a negligible drop in the model's actual intelligence and reasoning capabilities, making it a highly efficient trade-off for consumer use.[5]

Alongside quantization, the industry has seen the rapid rise of Small Language Models (SLMs). Rather than trying to build the biggest model possible, researchers have focused on training highly efficient, compact models—like Meta's Llama 3 8B or Microsoft's Phi-3 series. These SLMs are specifically engineered to punch above their weight class, offering the conversational fluency of a massive cloud model while remaining lightweight enough to run on a smartphone.[4][5]
The software layer has also undergone a massive democratization. Just a few years ago, running a local model required deep technical knowledge, command-line interfaces, and complex Python environments. Today, applications like Ollama and LM Studio have turned the process into a one-click app store experience. Users simply browse a catalog of models, click download, and immediately start chatting in a familiar, user-friendly interface.[3]

The software layer has also undergone a massive democratization.
However, the true enabler of the local AI era has been a fundamental shift in hardware architecture. Almost every new laptop sold in 2026 includes a Neural Processing Unit (NPU)—a dedicated chip designed exclusively to handle the complex matrix math required by artificial intelligence. Just as a GPU handles graphics, the NPU handles AI inference, freeing up the main processor to run the rest of the computer smoothly.[1][8]
Before NPUs became standard, running a local language model would cause a laptop's fans to spin wildly and drain the battery in under an hour. Modern NPUs process these models with incredible thermal efficiency. A user can now generate thousands of words of text or summarize massive documents locally while barely impacting their device's battery life or temperature.[1][7]

Beyond privacy, the offline capability of local AI has proven to be a massive draw. Users can now brainstorm ideas on a Wi-Fi-less airplane, code software in a remote cabin, or translate documents in areas with poor cellular reception. The AI becomes a permanent, reliable utility on the device, much like a calculator or a word processor, rather than a web service that goes down during server outages.[2][6]
Cost is another significant factor driving the trend. As the subscription fatigue of paying monthly fees for various cloud AI services sets in, local AI offers a compelling alternative: it is entirely free. Once the open-source model is downloaded, the user has unlimited, unrestricted access to it forever, with no usage caps or premium tiers.[1][3]
There are, of course, trade-offs to the local approach. A model compressed to fit on a laptop will never possess the sheer encyclopedic knowledge or advanced reasoning capabilities of a frontier cloud model running on thousands of server-grade GPUs. For highly complex coding tasks or cutting-edge scientific reasoning, cloud models remain the gold standard.[7]
Additionally, while NPUs have drastically improved efficiency, running continuous, heavy AI workloads locally will still degrade battery life faster than simply browsing the web. Users must balance their desire for privacy and offline access against the physical constraints of their device's hardware.[7]
The consensus among tech analysts is that the future of computing is hybrid. Operating systems, such as Apple's latest macOS and Windows 12, are now designed to route requests intelligently. If a user asks a simple question or requests a summary of a private email, the operating system processes it entirely locally. Only if the request is highly complex does the system—with explicit user permission—ping a larger cloud model.[1][8]
Ultimately, the rise of local AI represents a profound democratization of technology. By untethering artificial intelligence from corporate data centers and placing it directly into the hands of users, the tech community has ensured that the most transformative technology of the decade remains accessible, private, and resilient.[4][6]
How we got here
Early 2023
Meta's LLaMA model leaks online, sparking a grassroots movement of developers trying to run it on personal computers.
Late 2023
Breakthroughs in quantization allow massive models to be compressed enough to fit on standard laptop RAM.
2024
User-friendly applications like Ollama and LM Studio launch, making local AI accessible to non-programmers.
2025
Hardware manufacturers begin standardizing NPUs (Neural Processing Units) in consumer laptops to handle local AI workloads.
2026
Major operating systems adopt a hybrid approach, defaulting to local, on-device AI processing for everyday tasks to ensure privacy.
Viewpoints in depth
Privacy Advocates
View local AI as an essential defense against corporate data harvesting, prioritizing absolute data sovereignty.
For privacy advocates, the shift to local AI is the most important technological development since end-to-end encryption. They argue that sending personal journals, proprietary code, or confidential medical records to cloud providers creates an unacceptable security risk, regardless of a company's privacy policy. By running models locally, users achieve true data sovereignty—the mathematical certainty that their data cannot be intercepted, breached, or used to train future commercial models. This camp views local AI not just as a convenience, but as a fundamental digital right.
Open-Source Developers
Focus on the democratization of technology, building tools that allow anyone to tinker with and run models without gatekeepers.
The open-source community sees local AI as a way to break the oligopoly of massive tech corporations. They argue that if AI is going to be the foundational technology of the next decade, it cannot be controlled by a handful of companies guarding their models behind expensive API paywalls. By developing open-weight models and the software to run them, this camp is focused on democratization. They prioritize building tools that allow researchers, hobbyists, and startups to tinker, modify, and deploy AI solutions without needing millions of dollars in server infrastructure.
Hardware Manufacturers
See the local AI trend as a major driver for upgrading consumer hardware, emphasizing the power and efficiency of new NPU chips.
For companies that build laptops and silicon chips, the local AI boom is a massive commercial opportunity. After years of stagnant PC sales, the requirement for dedicated Neural Processing Units (NPUs) gives consumers a compelling reason to upgrade their devices. This camp focuses heavily on performance metrics—how many trillions of operations per second (TOPS) their chips can handle, and how efficiently they can run models without draining the battery. Their goal is to make the hardware so capable that the average consumer doesn't even realize their AI assistant is running locally.
What we don't know
- Whether open-source local models will ever fully close the reasoning gap with massive, proprietary cloud models.
- How regulators might attempt to control the distribution of uncensored, open-weight models that run locally.
- The long-term impact of continuous local AI processing on the physical lifespan of consumer laptop batteries.
Key terms
- Local AI / Edge AI
- Running artificial intelligence models directly on a personal device rather than relying on cloud servers.
- Quantization
- A compression technique that reduces the precision of an AI model's numbers, allowing it to take up significantly less memory.
- NPU (Neural Processing Unit)
- A specialized hardware chip designed specifically to handle the complex mathematics required by AI efficiently.
- SLM (Small Language Model)
- A compact AI model designed to be highly efficient and run on consumer hardware, as opposed to massive cloud-based models.
- Inference
- The process of an AI model generating a response or prediction based on a user's prompt.
Frequently asked
Can my current laptop run local AI?
Most laptops built in the last few years with at least 8GB of RAM can run small, quantized models. However, laptops built in 2024 or later with dedicated NPUs will run them much faster and with better battery life.
Is local AI as smart as ChatGPT?
Not quite. Local models are highly capable for writing, summarizing, and basic coding, but they lack the vast encyclopedic knowledge and advanced reasoning of massive cloud models like GPT-4.
Does it cost money to run AI locally?
No. The open-source models and the software used to run them (like Ollama or LM Studio) are completely free to download and use, with no subscription fees.
Does local AI require an internet connection?
Only for the initial download of the model and software. Once installed, the AI runs entirely offline.
Sources
Source coverage
8 outlets
3 viewpoints surfaced







[1]The VergeHardware Manufacturers
Why your next laptop is an offline AI powerhouse
Read on The Verge →[2]WiredPrivacy Advocates
The Ultimate Privacy Hack: Taking Your AI Offline
Read on Wired →[3]Ars TechnicaOpen-Source Developers
How tools like Ollama and LM Studio made local AI a one-click reality
Read on Ars Technica →[4]GitHub BlogOpen-Source Developers
The developer shift toward local open-source models
Read on GitHub Blog →[5]Hugging FaceOpen-Source Developers
State of Local Inference 2026: Quantization and SLMs
Read on Hugging Face →[6]TechCrunchHardware Manufacturers
Investors pivot to 'Edge AI' as consumers demand local processing
Read on TechCrunch →[7]MIT Technology ReviewHardware Manufacturers
The trade-offs of running AI on your own silicon
Read on MIT Technology Review →[8]Apple NewsroomPrivacy Advocates
Advancing on-device machine learning for absolute privacy
Read on Apple Newsroom →


Every angle. Every day.
Get meta stories with full source coverage and perspective breakdowns delivered to your inbox.