How Indigenous Communities are Reclaiming AI to Save Endangered Languages
Facing the potential loss of thousands of languages by the century's end, indigenous groups are building their own open-source AI models to preserve their linguistic heritage while fiercely protecting their data sovereignty.
By Factlen Editorial Team
- Indigenous Data Sovereignty Advocates
- Argue that language data is a cultural asset that must be protected from corporate extraction.
- Open-Source AI Developers
- Focus on lowering the technical barriers to entry through accessible, lightweight machine learning toolkits.
- Linguistic Preservationists
- Highlight the urgent, time-sensitive nature of recording endangered languages before fluent elders pass away.
What's not represented
- · Elders who are hesitant or opposed to digitizing sacred oral traditions
- · Commercial AI companies seeking to license indigenous data ethically
Why this matters
As artificial intelligence shapes the future of global communication, indigenous communities are proving that technology doesn't have to erase minority cultures. By building their own AI tools, they are ensuring their languages—and the unique worldviews they carry—survive the digital age on their own terms.
Key points
- Nearly half of the world's 7,000 languages are at risk of disappearing by the end of the century.
- Indigenous communities are building their own AI models to preserve their languages rather than relying on Big Tech.
- Frugal AI techniques allow highly accurate models to be trained with just hundreds of hours of audio data.
- Te Hiku Media built a te reo Māori speech-to-text model with 92% accuracy using crowdsourced community recordings.
- Data sovereignty ensures that cultural heritage is protected from commercial extraction and surveillance.
- Grassroots networks like Masakhane are proving that decentralized, community-led research can rival corporate AI labs.
The world is currently experiencing a silent extinction event of human heritage. According to UNESCO, nearly half of the world's 7,000 spoken languages are at risk of disappearing by the end of the century. When a language fades, it takes with it an entire worldview—unique ecological knowledge, oral histories, and cultural paradigms that cannot be perfectly translated into dominant tongues. For decades, the digital revolution accelerated this decline, as the internet and consumer technology overwhelmingly defaulted to a handful of "high-resource" languages like English, Mandarin, and Spanish, leaving marginalized dialects locked out of the modern digital ecosystem.[1][2]
But a profound shift is underway at the intersection of technology and cultural preservation. Rather than waiting for Silicon Valley to build tools for them, indigenous and underserved communities are reclaiming artificial intelligence to preserve their own linguistic heritage. By leveraging open-source technology and crowdsourced data, grassroots organizations are building custom speech-to-text models, translation engines, and pronunciation apps. This movement is not just about digital preservation; it is a fundamental fight for "data sovereignty"—the right of indigenous people to own, govern, and control their cultural data rather than surrendering it to multinational tech corporations.[2][5]
The primary technical hurdle in this endeavor has historically been the sheer volume of data required to teach a machine a new language. Traditional Natural Language Processing—the branch of artificial intelligence that helps computers understand human text and speech—relies on massive datasets scraped from the public internet. Building a standard commercial Automatic Speech Recognition system typically requires tens of thousands of hours of transcribed audio. For marginalized languages with few native speakers and minimal digital footprints, assembling that much data is mathematically impossible, effectively redlining them out of the AI revolution.[3][4]

To solve this structural inequity, researchers and community technologists are turning to "frugal AI." Frugal AI involves lightweight machine learning architectures and transfer-learning techniques that require drastically less data and computing power. Instead of starting from scratch, developers can take a foundational open-source language model and fine-tune it using a highly curated, much smaller dataset. This approach dramatically lowers the barrier to entry, allowing small community groups to train highly accurate, bespoke models using consumer-grade hardware or accessible cloud-based open-source toolkits.[4][6]
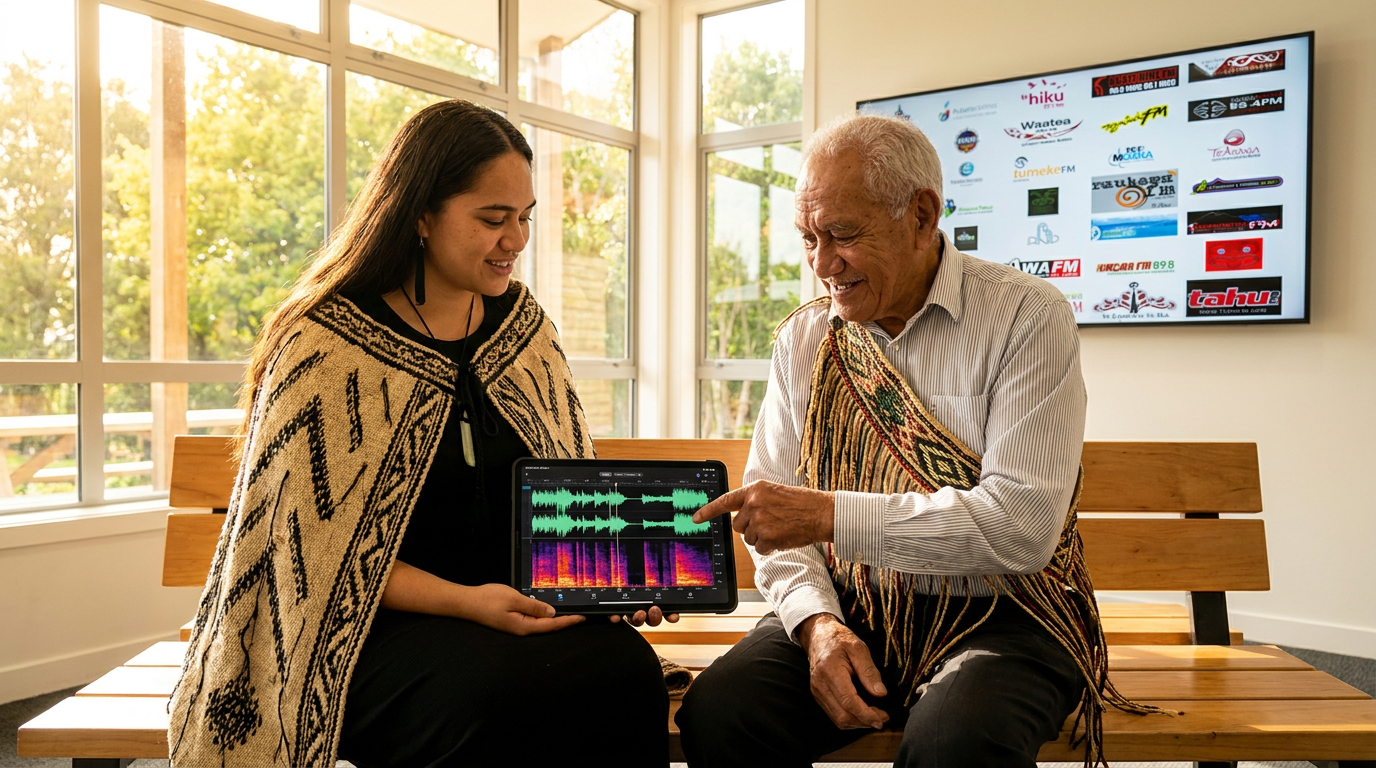
The most striking success story of this approach comes from Aotearoa (New Zealand), where Te Hiku Media, a Māori broadcasting organization, has built a world-class speech recognition model for te reo Māori. Recognizing that the language was largely spoken by an aging population, Te Hiku launched an open-source application called Korero Maori to crowdsource voice data directly from the community. The response was unprecedented: in just ten days, over 2,500 community members recorded themselves reading phrases, generating more than 300 hours of meticulously labeled speech data.[1][2]
Using the open-source NVIDIA NeMo toolkit, Te Hiku Media trained a speech-to-text model that now transcribes te reo Māori with an impressive 92 percent accuracy. The technology currently powers bilingual live-stream captioning and an application called Rongo, which helps younger generations practice authentic pronunciation without assimilating to English phonetics. Crucially, Te Hiku achieved this technological milestone without uploading their historical archives to platforms like YouTube or SoundCloud, which often claim broad, irrevocable rights to create derivative works from user-uploaded content.[1][2]

Using the open-source NVIDIA NeMo toolkit, Te Hiku Media trained a speech-to-text model that now transcribes te reo Māori with an impressive 92 percent accuracy.
This strict insistence on data sovereignty is a defining pillar of the indigenous AI movement. For many indigenous groups, data is viewed as the "new land," and allowing tech giants to scrape their elders' voices to train proprietary, monetized AI models is seen as a modern form of digital colonialism. To protect their heritage, Te Hiku Media operates under a Kaitiakitanga (guardianship) license, ensuring that the data remains strictly under community control and cannot be used for surveillance, discrimination, or commercial exploitation without explicit consent.[2][5]
This decentralized, community-first approach to artificial intelligence is spreading rapidly across the globe. Across the African continent, a grassroots organization called Masakhane—which translates to "We build together" in isiZulu—has mobilized a network of over 1,000 researchers spanning 30 countries. Masakhane's mission is to spur natural language processing research for African languages, strictly by Africans. They have successfully published open-source machine translation baselines for dozens of languages that commercial platforms have historically ignored, proving that participatory, distributed research can rival the output of well-funded corporate labs.[3]
Similarly, in North America, the First Languages AI Reality initiative, backed by the Mila Quebec AI Institute, is laying the groundwork for Native American language preservation. The initiative focuses on developing rapid speech recognition creation methods that explicitly respect linguistic self-determination. By building these tools, they aim to enable indigenous youth to interact with emerging technologies—from voice assistants to immersive digital environments—entirely in their heritage languages, facilitating vital intergenerational transmission that might otherwise be lost to English assimilation.[4]

Despite these remarkable breakthroughs, significant uncertainties and challenges remain for the movement. The most pressing issue is the unforgiving race against time. For many critically endangered languages, the last fluent elders are passing away before their voices can be adequately recorded, transcribed, and annotated by the community. Furthermore, capturing the deep nuances, regional dialects, and highly contextual grammar of complex indigenous languages remains a formidable technical challenge. It requires intense manual labor and specialized linguistic expertise to ensure accuracy, even when utilizing the most advanced frugal AI techniques available today.[1][4]
There is also an ongoing, delicate tension between the broader tech industry's open-source ideals and the specific need for indigenous cultural protection. While open-source software democratizes access to powerful artificial intelligence tools, indigenous communities must carefully navigate how to share their trained models without inadvertently allowing bad actors to appropriate their linguistic data. Balancing the desire for open, global collaboration with the absolute necessity of strict data sovereignty requires constant legal, ethical, and technical vigilance from community leaders who are charting entirely new territory in digital rights.[5][6]
Ultimately, the intersection of indigenous knowledge and artificial intelligence represents a powerful reclaiming of the digital future. By building their own independent digital infrastructure and secure "houses of speech," these communities are actively proving that cutting-edge technology does not have to be an assimilating or extractive force. Instead, when designed and guided by the people who actually hold the culture, artificial intelligence can become a vital, empowering instrument for ensuring that the world's oldest and most unique voices continue to resonate clearly in the modern era.[6]
How we got here
2014
Te Hiku Media begins digitizing archives of Māori speakers born in the late 19th century to preserve the language.
2020
The Masakhane community publishes its first major papers demonstrating successful participatory NLP research for African languages.
2022
Te Hiku Media launches the Korero Maori app, crowdsourcing over 300 hours of indigenous language recordings in just ten days.
2024
Open-source toolkits like NVIDIA NeMo enable grassroots organizations to achieve over 90% transcription accuracy for historically marginalized languages.
Viewpoints in depth
Indigenous Data Sovereignty Advocates
Argue that language data is a cultural asset that must be protected from corporate extraction.
This camp emphasizes that historical colonization often involved the extraction of physical resources, and modern digital practices risk repeating this pattern with data. They argue that uploading elders' voices to commercial platforms surrenders intellectual property. For these advocates, the primary goal is not just building functional AI, but ensuring that the community retains absolute legal and technical ownership over the models and the underlying datasets.
Open-Source AI Developers
Focus on lowering the technical barriers to entry through accessible, lightweight machine learning toolkits.
Technologists in this space prioritize the democratization of artificial intelligence. They argue that the future of NLP lies in 'frugal AI'—models that can achieve high accuracy without requiring the massive server farms and petabytes of data used by Silicon Valley giants. By providing open-source frameworks like NVIDIA NeMo or Hugging Face libraries, they aim to give grassroots organizations the building blocks needed to construct their own bespoke solutions.
Linguistic Preservationists
Highlight the urgent, time-sensitive nature of recording endangered languages before fluent elders pass away.
For linguists and cultural historians, the primary concern is the ticking clock. With thousands of languages projected to disappear by the end of the century, this camp views AI as a critical emergency intervention. They advocate for rapid, widespread deployment of crowdsourcing apps to capture oral histories, idioms, and phonetic nuances immediately, arguing that perfect data sovereignty frameworks shouldn't delay the urgent task of recording aging speakers.
What we don't know
- Whether enough data can be collected for the most critically endangered languages before their last fluent elders pass away.
- How indigenous communities will legally enforce data sovereignty across international borders if their open-source models are misused.
- The extent to which frugal AI can accurately capture the deepest contextual nuances and regional dialects of highly complex languages.
Key terms
- Automatic Speech Recognition (ASR)
- Technology that converts spoken language into written text, serving as the foundation for voice assistants and transcription tools.
- Data Sovereignty
- The principle that indigenous communities have the right to own, control, and govern the collection and application of their own cultural data.
- Natural Language Processing (NLP)
- A branch of artificial intelligence that focuses on enabling computers to understand, interpret, and generate human language.
- Frugal AI
- Machine learning approaches designed to operate efficiently with limited data, computing power, and financial resources.
Frequently asked
What is a low-resource language?
A low-resource language is one that lacks large amounts of digital text or audio data, making it difficult to train traditional artificial intelligence models like translation software or voice assistants.
Why don't communities just use Google Translate?
Many indigenous languages are not supported by commercial platforms. Furthermore, communities often want to retain ownership of their cultural data rather than surrendering it to large tech corporations.
What is frugal AI?
Frugal AI refers to lightweight machine learning models and techniques that can be trained efficiently using significantly less data and computing power than traditional commercial models.
What is data sovereignty?
Data sovereignty is the principle that indigenous communities have the inherent right to own, control, and govern the collection and application of their own cultural and linguistic data.
Sources
Source coverage
6 outlets
3 viewpoints surfaced






[1]NVIDIA BlogOpen-Source AI Developers
How Trustworthy AI Helps Preserve the Māori Language
Read on NVIDIA Blog →[2]ITU HubLinguistic Preservationists
Preserving indigenous languages with AI
Read on ITU Hub →[3]MasakhaneOpen-Source AI Developers
Masakhane: NLP for Africans, by Africans
Read on Masakhane →[4]Mila - Quebec AI InstituteLinguistic Preservationists
First Languages AI Reality (FLAIR)
Read on Mila - Quebec AI Institute →[5]Olin CollegeIndigenous Data Sovereignty Advocates
Keoni Mahelona '07 is a leader in indigenous sovereignty of data and technologies
Read on Olin College →[6]Factlen Editorial TeamIndigenous Data Sovereignty Advocates
Synthesis by Factlen editorial team
Read on Factlen Editorial Team →
Every angle. Every day.
Get community stories with full source coverage and perspective breakdowns delivered to your inbox.